IndexFiguresTables |
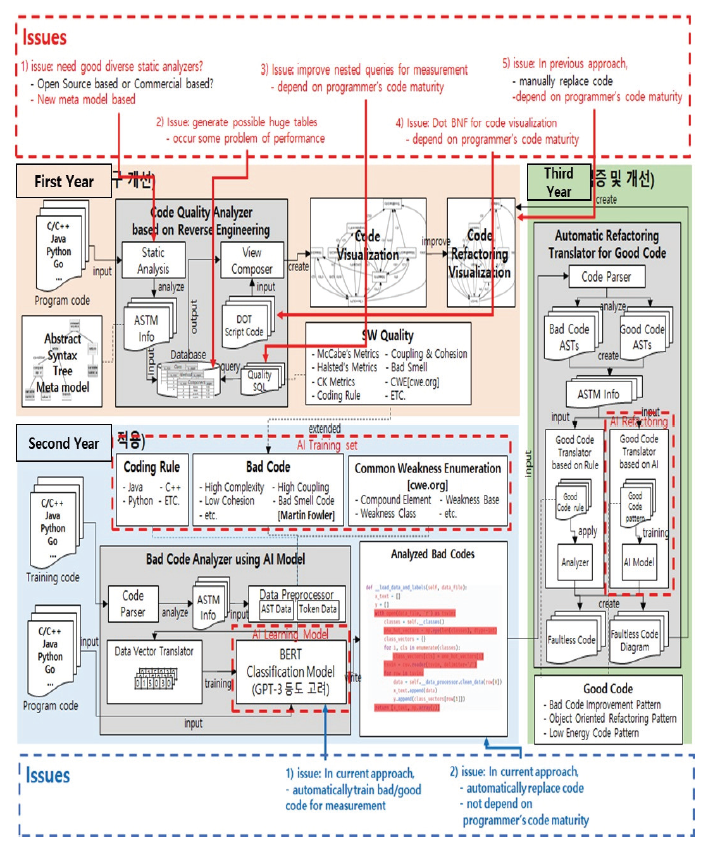
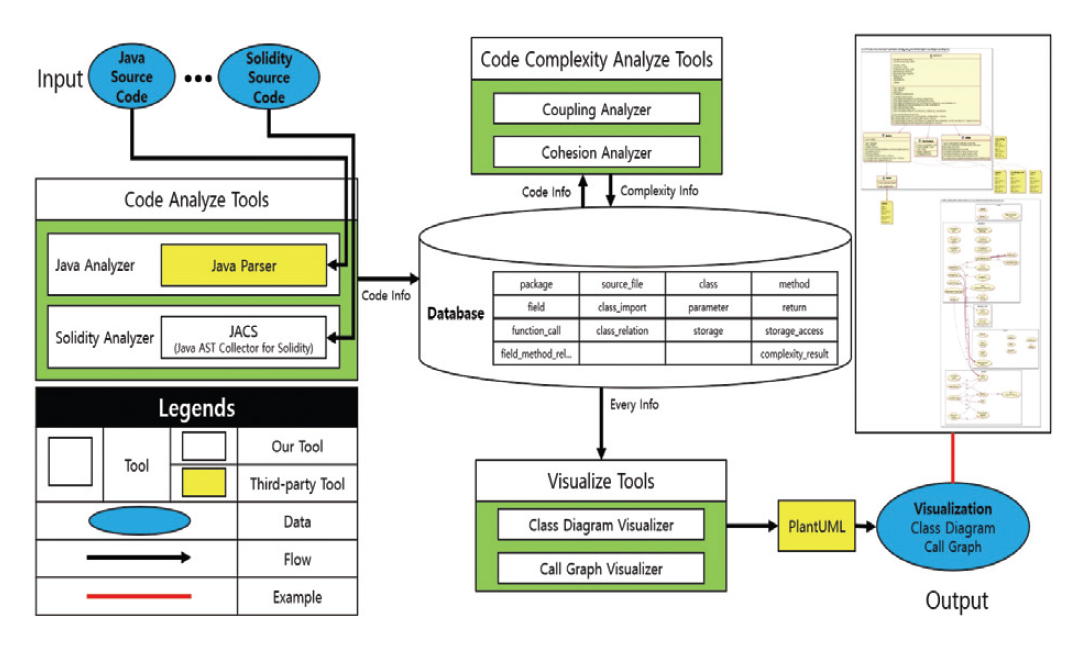
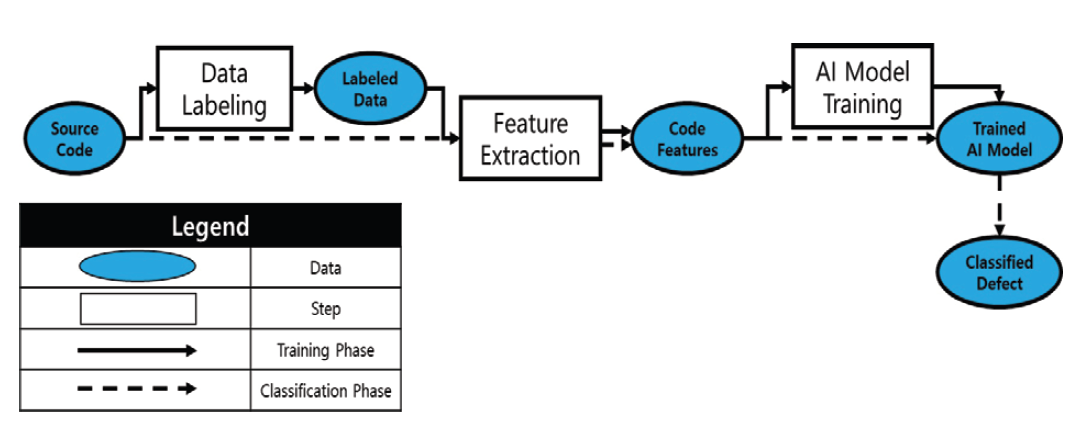
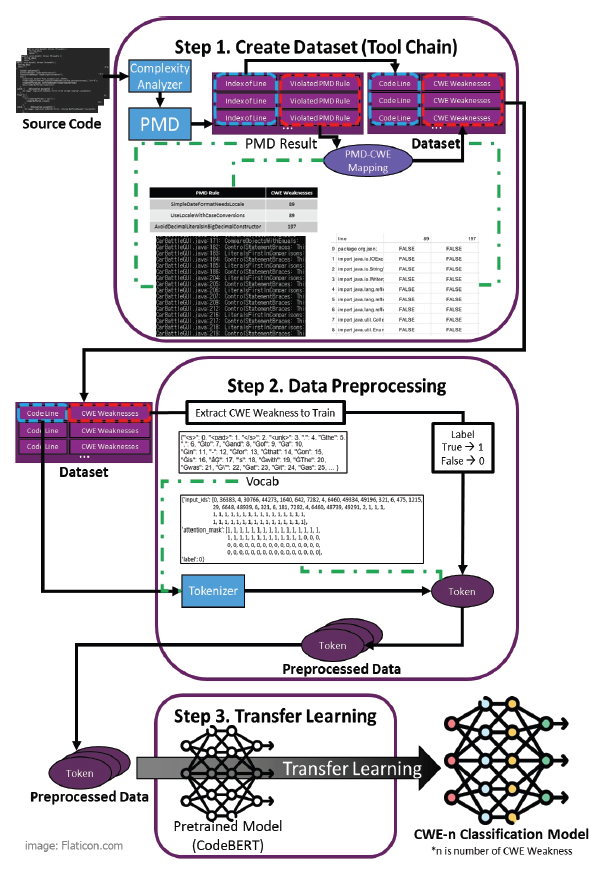
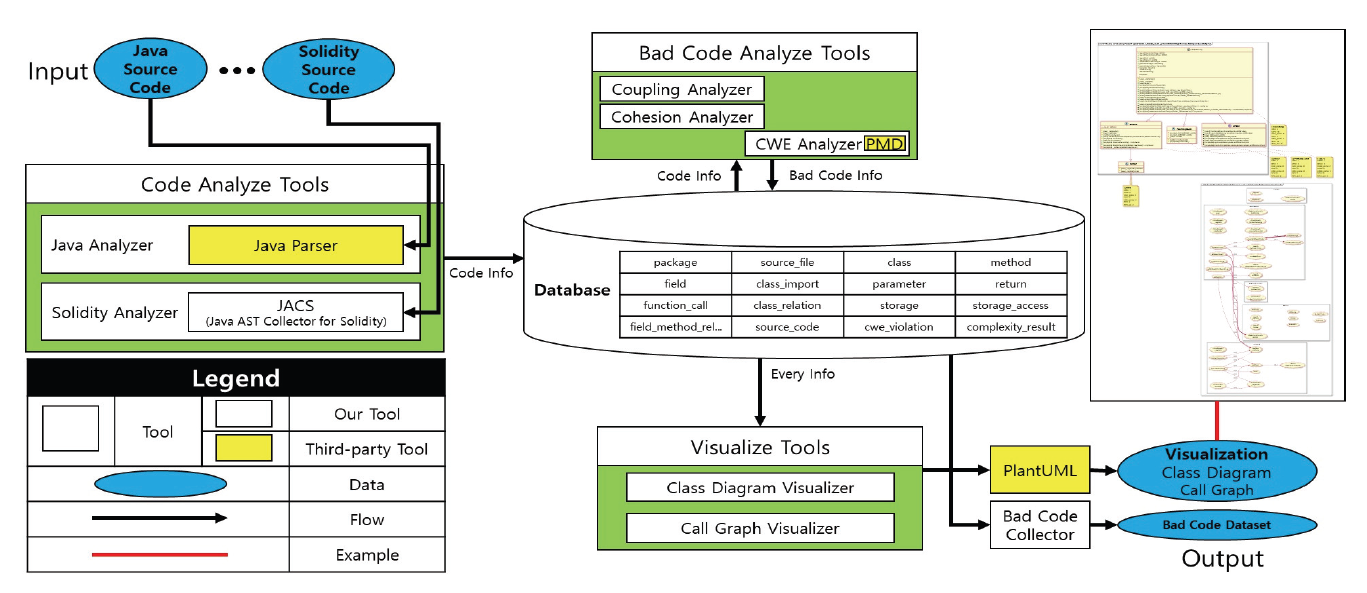
Chansol Park† , So Young Moon†† and R. Young Chul Kim†††Detecting Common Weakness Enumeration(CWE) Based on the Transfer Learning of CodeBERT ModelAbstract: Recently the incorporation of artificial intelligence approaches in the field of software engineering has been one of the big topics. In the world, there are actively studying in two directions: 1) software engineering for artificial intelligence and 2) artificial intelligence for software engineering. We attempt to apply artificial intelligence to software engineering to identify and refactor bad code module areas. To learn the patterns of bad code elements well, we must have many datasets with bad code elements labeled correctly for artificial intelligence in this task. The current problems have insufficient datasets for learning and can not guarantee the accuracy of the datasets that we collected. To solve this problem, when collecting code data, bad code data is collected only for code module areas with high-complexity, not the entire code. We propose a method for exploring common weakness enumeration by learning the collected dataset based on transfer learning of the CodeBERT model. The CodeBERT model learns the corresponding dataset more about common weakness patterns in code. With this approach, we expect to identify common weakness patterns more accurately better than one in traditional software engineering. Keywords: Software Engineering , Code Visualization , Code Complexity , Code Weakness , Artificial Intelligence 박찬솔†, 문소영††, 김영철†††CodeBERT 모델의 전이 학습 기반 코드 공통 취약점 탐색요 약: 소프트웨어 공학 영역에 인공지능의 접목은 큰 화두 중 하나이다. 전 세계적으로 1) 인공지능을 통한 소프트웨어 공학, 2) 소프트웨어 공학을 통한 인공지능 두 가지 방향으로 활발히 연구되고 있다. 그 중 소프트웨어 공학에 인공지능을 접목하여 나쁜 코드 영역을 식별하고 해당 부분을 리팩토링하는 연구가 진행되고 있다. 해당 연구에서 인공지능이 나쁜 코드 요소의 패턴을 잘 학습하기 위해서는 학습하려는 나쁜 코드 요소가 라벨링 된 데이터셋이 필요하다. 문제는 데이터셋이 부족할뿐더러, 자체적으로 수집한 데이터셋의 정확도는 신뢰할 수 없다. 이를 해결하기 위해 코드 데이터 수집 시 전체 코드가 아닌 높은 복잡도를 가진 코드 모듈 영역을 대상으로만 나쁜 코드 데이터를 수집한다. 이후 수집한 데이터셋을 CodeBERT 모델의 전이 학습하여 코드 공통 취약점을 탐색하는 방법을 제안한다. 해당 데이터셋을 통해 CodeBERT 모델이 코드의 공통 취약점 패턴을 더 잘 학습할 수 있다. 이를 통해 전통적인 방법보다 인공지능 모델을 이용해 코드를 분석하고 공통 취약점 패턴을 더 정확하게 식별할 수 있을 것으로 기대한다. 키워드: 소프트웨어 공학, 코드 가시화, 코드 복잡도, 코드 취약점, 인공지능 1. 서 론소프트웨어 가시화는 품질 지표에 대한 추출을 통해 저품질 코드 영역을 식별하고 이를 리팩토링 할 수 있도록 나타내어, 소프트웨어를 고품질화하는 기법이다. 현재 소프트웨어 가시화 기법은 대부분 사람에 의해 구현된 규칙을 통해 품질 지표를 추출한다. 따라서 새로운 품질 지표를 측정하기 위해 반드시 새로운 규칙을 구현해줘야만 한다. 새로운 규칙의 구현은 다양한 변수와 이에 따라 발생하는 다양한 경우의 수를 모두 고려해야 하므로 많은 시간과 노력이 필요한 작업이다. 현재 소프트웨어 공학과 인공지능을 접목하는 연구가 활발히 진행되고 있다[1]. 그 중, 소프트웨어 가시화 기법에 인공지능을 접목하여 고도화하는 연구가 진행되고 있다. 해당 연구는 인공지능이 코드의 패턴을 학습하고 소프트웨어를 가시화한다. 이후, 전통적인 소프트웨어 공학적인 방법의 소프트웨어 가시화와 인공지능을 통한 소프트웨어 가시화를 비교하고자 한다. 본 논문에서는 CodeBERT 모델에 나쁜 코드의 전이 학습을 통해 모델이 스스로 나쁜 코드 패턴을 학습하는 방법을 제안한다. 해당 방법을 코드에 대한 공통 취약점 목록(Common Weakness Enumeration)에 적용한다. 이를 통해 인공지능이 소스 코드로부터 공통 취약점의 패턴을 스스로 학습하고 식별할 수 있다. 논문의 구조는 다음과 같다. 2장에서는 기존 코드 가시화 연구, 기존 인공지능 기반 코드 취약점 학습 연구, CodeBERT 모델, 공통 취약점 목록 그리고 Programming Mistake Detector(PMD) 도구에 대해 설명한다. 3장에서는 본 논문의 주제인 CodeBERT 모델의 전이 학습 기반 코드 공통 취약점 탐색을 설명한다. 4장에서는 코드 공통 취약점 항목에 관한 적용 사례를 설명한다. 마지막으로 결론 및 향후 연구를 언급한다. 2. 관련 연구2.1 코드 가시화 연구코드 가시화는 코드를 분석하여 추출한 정보를 표와 다이어그램 등으로 가시화하는 것이다. 이를 통해 소프트웨어의 비가시적인 특성을 극복하여 소프트웨어 개발 프로젝트에 관련된 이해 관계자가 알기 쉽게, 소프트웨어의 각 설계 및 복잡도, 결함 부위에 대한 가이드 등을 나타낼 수 있다[2-6]. Fig. 1은 소프트웨어 가시화 연구에 인공지능을 접목하여 고도화하는 연구 과정과 내용을 요약하여 정리한 그래프이다. 해당 연구는 1차 연도에 소프트웨어의 품질 검증을 위한 정적 분석기 및 코드 가시화 기술을 개발하고, 2차 연도는 인공지능 모델에 대한 학습을 통한 무결점 소프트웨어 코드 자동 생성 기술을 개발하고, 3차 연도는 소프트웨어의 품질 역량 강화를 위한 무결점 코드 가시화 서비스를 구축한다. Fig. 2는 기존 규칙 기반의 코드 가시화 툴 체인의 구조도이다[7]. 툴체인은 코드 분석 도구, 코드 복잡도 분석 도구 그리고 코드 가시화 도구 세 개의 도구로 이루어져 있다. 코드 분석 도구는 대상 프로그래밍 언어에 맞는 정적 분석 도구를 이용해 대상 코드를 분석 후 정보를 추출한다. 추출된 코드 정보는 데이터베이스에 저장된다. 코드 복잡도 분석 도구는 데이터베이스에 저장된 코드의 정보를 통해 객체지향 결합도와 응집도 등의 복잡도를 계산한다. 계산된 복잡도 또한 데이터 베이스에 저장된다. 코드 가시화 도구는 데이터베이스에 저장된 코드의 정보를 바탕으로 설계와 복잡 모듈을 가시화한다. 코드 복잡도는 코드가 복잡한 정도를 나타내는 품질 지표이다. 코드 복잡도 분석 도구에서는 각 복잡도에 대한 규칙을 통해 복잡도를 계산한다. Fig. 3은 CK Metric[10] 중 하나인 Coupling Between Object(CBO)를 계산하는 규칙이다. CBO는 하나의 클래스가 연결된 다른 클래스의 개수이다. CBO를 계산하는 규칙은 클래스 간 상속, 구현, 연관 등의 관계를 찾아 클래스가 연결된 다른 클래스의 개수를 계산한다. 2.2 기존 인공지능 기반 코드 취약점 학습 연구Fig. 4는 머신러닝을 통해 결함을 예측하는 모델의 일반적인 파이프라인이다[8]. 인공지능 모델에 결함을 학습하는 일반적인 과정은 다음과 같다. 우선 소스 코드를 클래스, 모듈, 함수 등의 단위로 쪼갠다. 이후 나누어진 소스 코드 단위의 특징을 추출하고, 취약점의 유무를 라벨링 한다. 이후 추출된 특징과 취약점으로 인공지능 모델을 훈련한다. 대부분의 연구는 Halstead Metric[9], CK Metric, McCabe’s Cyclomatic Complexity[11] 등의 코드 품질 지표들을 소스 코드의 특징으로써 추출한다. 이외에도 Code Bad Smell[12], Abstract Syntax Tree를 특징으로써 학습에 이용하는 경우가 있으며, 코드 그 자체를 모델에 입력하여 사용하는 연구는 매우 드물다. 현재 많이 사용되고 있는 규칙 기반 결함 탐지 도구는 코드의 어떤 줄이 어떤 취약점에 노출되어 있는지 표시한다. 반면에 코드를 함수, 모듈, 클래스 단위로 쪼개어 특징을 추출하고 학습하는 방법은 코드의 어떤 부분이 결함의 원인인지 정확히 알기가 어렵다는 문제점이 있다. 2.3 CodeBERT 모델BERT 모델은 Google에서 발표한 자연어 처리 모델이다[13]. Attention 메커니즘은 입력과 출력 간의 의존성을 모델링하고, 이를 통해 출력을 예측하기에 적합한 입력을 추천하는 메커니즘이다. Attention 층은 주로 기존의 RNN 및 LSTM 모델의 단기 기억 능력을 긴 시간 동안 유지하기 위한 용도로 사용되었다. Google에서는 Attention 층으로만 구성된 학습 모델인 Transformer 모델을 발표하였고, 이는 기존 Attention 층이 포함된 RNN 계열의 모델들보다 특히 자연어 처리 문제에서 개선된 성능을 보였다[14]. BERT는 Transformer 모델을 대용량의 데이터를 통해 사전 학습한 모델이며, 상대적으로 적은 양의 데이터를 통한 전이 학습으로도 높은 성능을 끌어낼 수 있다. CodeBERT는 Transformer 모델에 대해 자연어가 아닌 6가지의 프로그래밍 언어 (Python, Java, JavaScript, PHP, Ruby, Go)에 대해 사전 학습한 모델이다[15]. 따라서 해당 모델에 대한 전이 학습을 통해 프로그래밍 언어와 관련된 문제를 해결하는 모델을 비교적 쉽게 학습할 수 있다. 2.4 공통 취약점 목록(Common Weakness Enumeration)공통 취약점 목록은 커뮤니티를 통해 개발된 소프트웨어 및 하드웨어에서 일반적으로 식별할 수 있는 취약점들을 목록화 한 것이다[16]. 공통 취약점 목록은 프로그램에 대한 취약점의 식별 기준 및 취약점의 완화와 방지의 기준선의 역할을 한다. 소프트웨어 공통 취약점 목록은 소프트웨어의 설계, 아키텍처, 코드 등에 존재하는 취약점을 담고 있다. 2.5 Programming Mistake DetectorPMD는 프로그램의 취약점을 찾는 소스 코드 분석 오픈소스 도구이다[17]. Java, JavaScript 등 다양한 프로그래밍 언어에 대한 취약점 식별을 지원하며, Copy-Paste-Detector 도구가 내장되어 있어 중복 코드에 대해서도 탐지할 수 있다. PMD는 기본적으로 각 언어에 대해 다양한 취약점 규칙 들을 포함한다. 또한, 필요시 사용자 정의 규칙을 정의하여 새로운 취약점 혹은 사용자가 원하는 패턴의 코드를 식별할 수 있다. 3. CodeBERT 모델의 전이 학습 기반 코드 공통 취약점 탐색Fig. 5는 CodeBERT 모델에 코드 공통 취약점을 전이 학습하는 과정의 구조도이다. CodeBERT 모델에 대한 전이 학습 과정에서는 크게 데이터셋 수집 단계, 데이터셋 전처리 단계 그리고 전이 학습 진행 단계가 있다. 3.1 데이터셋 수집기존 나쁜 코드 패턴의 지도 학습을 통한 나쁜 코드 식별 연구[18]는 PMD 도구를 이용하여 데이터셋을 생성했다. 이 과정에서 PMD 도구 오탐지 한 코드 공통 취약점이 데이터셋에 포함될 수 있다. 오탐지 취약점은 인공지능 모델이 취약점의 패턴을 학습하는 것을 방해하고, 모델의 성능을 저해한다. Fig. 6은 공통 취약점 검출 도구(CWE Analyzer)가 추가된 코드 가시화 툴체인이다[19]. 공통 취약점 검출 도구는 나쁜 코드 분석 도구에 포함되는 도구로서 PMD를 통해 코드로부터 취약점을 식별한다. 식별된 PMD 취약점은 PMD 취약점 목록과 공통 취약점 목록 간의 매핑 테이블을 통해 공통 취약점의 ID로 변환된다. 이후 공통 취약점이 발견된 코드 라인의 ID와 식별된 공통 취약점을 데이터베이스에 기록한다. 코드 복잡도는 코드의 취약점과 큰 상관관계 갖고 있다[20]. 또한 기존 인공지능 기반의 코드 취약점 학습 연구에서도 측정한 코드의 복잡도를 코드의 특징으로써 추출하여 학습 및 결함 예측에 사용했다. 따라서 수집하는 데이터셋의 오탐지 취약점 반영을 줄이고 신뢰도를 높이기 위해 코드 복잡도를 적용한다. 툴체인은 산출물로서 복잡도가 높은 클래스의 취약점 식별 결과를 데이터셋으로 만든다. 이를 통해 PMD 도구만을 사용하여 수집된 데이터셋보다 신뢰도가 높은 데이터셋을 수집할 수 있다. 3.2 데이터셋 전처리CodeBERT 모델에 코드 라인의 공통 취약점 항목 패턴을 학습하기 위해 데이터셋을 전처리한다. 데이터 전처리 단계는 공통 취약점 항목 추출, 코드 라인 데이터 정제, 토큰화 그리고 클래스 균형 4개의 과정으로 나눌 수 있다. 공통 취약점 항목 추출 과정에서는 데이터셋에서 모델 학습에 필요한 데이터만 추출한다. CodeBERT 모델이 특정 공통 취약점 항목을 학습하는 것이 목적이기 때문에 학습할 공통 취약점 항목의 라벨과 코드 라인을 추출한다. 코드 라인 데이터 정제 과정에서는 취약점 식별과 관련 없는 노이즈를 제거하는 작업을 진행한다. 주석 혹은 공백만이 포함된 코드 라인은 공통 취약점과는 크게 연관이 없다. 따라서 이러한 노이즈를 학습 데이터셋으로부터 제거한다. 토큰화 과정에서는 CodeBERT 모델의 사전학습 Tokenizer를 통해 코드 라인을 토큰 시퀀스로 변환한다. 변환된 토큰 시퀀스에 대해 공통 취약점 라벨을 추가한다. 학습 데이터의 클래스 불균형 문제는 인공지능 모델의 학습을 저하하는 요인 중 하나이다. 수집한 데이터셋에는 취약한 코드 라인보다 취약하지 않은 코드 라인이 훨씬 많다. 이를 해결하기 위해 취약한 코드 라인 데이터를 증폭하는 오버샘플링 기법과 취약하지 않은 코드 라인의 개수를 줄이는 언더샘플링 기법을 적용할 수 있다. 3.3 CodeBERT 모델에 대한 전이 학습앞선 두 단계를 통해 수집 및 전처리 된 학습 데이터셋을 통해 CodeBERT 모델에 대해 전이 학습을 진행한다. 이를 통해 CodeBERT 모델이 특정 공통 취약점 항목의 패턴 학습한다. 학습이 끝난 모델은 입력된 코드 라인에 대해 취약한 코드라인인지 식별한다. 이때 모델이 과적합 되지 않고 잘 학습될 수 있도록 학습률, 학습 횟수 등을 조절할 수 있다. 4. 적용 사례적용 사례로서 ‘CWE-400: Uncontrolled Resource Consumption’ 항목의 패턴을 CodeBERT 모델에 학습한다. PMD만을 이용해 수집한 데이터와 툴체인을 통해 수집한 데이터로 각각 모델을 학습하고, Juliet Java 1.3[21]로 테스트한 결과를 비교한다. Table 1은 PMD만을 이용해 수집한 데이터의 정보이다. PMD 도구를 이용해 9,280개의 깃허브 오픈소스 JAVA 프로젝트로부터 50,923개의 소스 코드에 대해 취약점의 검출 여부를 라벨링 했다. 이를 통해 총 11,893,126줄의 코드 라인에 대해 250,918줄의 취약점이 있는 코드 라인과 11,642,208줄의 취약점이 검출되지 않은 코드 라인으로 분류했다. True와 False로 라벨링 된 데이터 간 데이터 불균형을 언더샘플링 기법을 통해 균형을 맞췄다. Table 1. Data Labeled by PMD
Table 2는 코드 가시화 툴체인을 통해 수집한 데이터의 정보이다. 툴체인을 통해 1,630개의 깃허브 오픈소스 JAVA 프로젝트로부터 66,504개의 클래스에 대해 취약점의 검출 여부를 라벨링 했다. 이를 통해 총 10,705,865줄의 코드 라인에 대해 7,981줄의 취약점이 있는 코드 라인과 10,705,865줄의 취약점이 검출되지 않은 코드 라인으로 분류했다. PMD를 통해 수집된 데이터와 마찬가지로 True와 False로 라벨링 된 데이터 간 불균형이 매우 심하므로 언더샘플링 기법을 통해 균형을 맞췄다. Table 2. Data Labeled by Code Visualization Tool Chain
학습된 모델들의 테스트 방법으로서 Juliet Java 1.3을 이용한다. 해당 데이터셋은 National Institute of Standards and Technology에서 배포하는 공통 취약점 목록에 대한 테스트 케이스 묶음으로서 보안 도구 및 취약점 검출 도구에 대한 검증 데이터셋으로써 보편적으로 사용된다. Juliet Java 1.3에는 각 공통 취약점 항목에 대해 나쁜 경우와 좋은 경우의 함수로 나뉜다. 이때 나쁜 경우의 함수에는 나쁜 Source로부터 입력된 데이터를 나쁜 Sink를 통해 처리하는 경우가 포함된다. 좋은 경우의 함수에는 나쁜 Source로부터 입력된 데이터를 좋은 Sink로 처리하는 경우 혹은 좋은 Source로부터 입력된 데이터를 나쁜 Sink를 통해 처리하는 경우가 포함된다. 따라서 좋은 경우의 함수임에도 불구하고 취약점 요소가 포함된 경우가 많다. 따라서 모델은 좋은 경우의 함수에 포함된 취약점 라인을 검출하고, 나쁜 경우의 함수로 구분할 수 있다. 따라서 모델 테스트 시 나쁜 함수에 대한 취약점 식별 정확도에 대해서만 고려한다. Table 3은 PMD 도구를 통해 수집한 데이터로 학습한 모델의 검증 혼동행렬이다. Table 4는 코드 가시화 툴체인을 통해 수집한 데이터로 학습한 모델의 검증 혼동행렬이다. 식별 정확도는 모든 Bad Case에 대해 True로 분류한 Bad Case의 비율이다. Table 3 혼동행렬에서의 식별 정확도는 약 80.21%이다. Table 4 혼동행렬에서의 식별 정확도는 약 83.04%이다. 두 모델 모두 언더샘플링을 통해 데이터 불균형 문제를 해결했다. 학습에 이용된 PMD 데이터셋은 501,836줄이며, 코드 가시화 툴체인 데이터셋은 15,962줄이다. 툴체인으로 수집된 데이터셋으로 학습한 모델이 더 적은 양의 데이터로 학습했음에도 불구하고, 나쁜 케이스의 함수에 대해 더 취약점을 잘 검출했다. 5. 결 론본 논문에서는 CodeBERT 모델에 나쁜 코드의 패턴을 전이 학습하여 나쁜 코드를 식별하는 방법을 제안하였다. 이를 공통 취약점에 적용하여 취약점의 패턴을 모델에 학습했다. 학습한 모델을 Juliet Java 1.3에 포함된 함수를 분류하여 식별 정확도를 테스트하였다. 이러한 방법을 통해 CodeBERT 모델이 취약점의 패턴을 학습할 수 있다. 또한 복잡도가 높은 클래스에 대해 수집한 데이터를 통해 인공지능 모델이 취약점의 패턴을 더 잘 학습할 수 있다. 이를 통해 새로운 유형의 취약점 혹은 규칙을 정하기 까다로운 취약점에 대해 CodeBERT 모델이 패턴을 스스로 학습하는 것을 기대한다. 추후 더 많은 데이터에 대한 학습을 통해 모델이 식별할 수 있는 나쁜 코드의 종류를 늘이고 정확도를 향상할 것이다. 이때 데이터셋의 정확도 향상을 위해 복잡도 외의 추가적인 지표를 기준으로 나쁜 코드를 수집하는 것을 고려한다. 이후 이를 규칙 기반의 도구와 비교를 통해 성능을 비교 및 검증하는 연구를 할 것이다. 또한, 나쁜 코드가 식별된 모듈 영역에 대해 인공지능으로 리팩토링하는 연구도 진행할 예정이다. BiographyBiographyBiographyReferences
|
StatisticsHighlights트윗 텍스트 마이닝 기법을 이용한 구제역의 감성분석H. Chae, J. Lee, Y. Choi, D. Park, Y. Chung오픈 소스 라이선스 양립성 위반 식별 기법 연구D. Lee and Y. Seo향상된 음향 신호 기반의 음향 이벤트 분류Y. Cho, J. Lee, D. Park, Y. Chung3차원 가상 실내 환경을 위한 심층 신경망 기반의 장면 그래프 생성D. Shin and I. Kim생성적 적대 네트워크로 자동 생성한 감성 텍스트의 성능 평가C. Park, Y. Choi, K. J. Lee암 예후를 효과적으로 예측하기 위한 Node2Vec 기반의 유전자 발현량 이미지 표현기법J. Choi and S. Park단일 영상에서 눈송이 제거를 위한 지각적 GANW. Wan and H. J. Lee궤적 데이터 스트림에서 동반 그룹 탐색 기법S. Kang and K. Y. Lee하둡을 이용한 3D 프린터용 대용량 데이터 처리 응용 개발K. E. Lee and S. Kim국민청원 주제 분석 및 딥러닝 기반 답변 가능 청원 예측W. Y. Hui and H. H. KimCite this articleIEEE StyleC. Park, S. Y. Moon, R. Y. C. Kim, "Detecting Common Weakness Enumeration(CWE) Based on the Transfer Learning of CodeBERT Model," KIPS Transactions on Software and Data Engineering, vol. 12, no. 10, pp. 431-436, 2023. DOI: https://doi.org/10.3745/KTSDE.2023.12.10.431.
ACM Style Chansol Park, So Young Moon, and R. Young Chul Kim. 2023. Detecting Common Weakness Enumeration(CWE) Based on the Transfer Learning of CodeBERT Model. KIPS Transactions on Software and Data Engineering, 12, 10, (2023), 431-436. DOI: https://doi.org/10.3745/KTSDE.2023.12.10.431.
|
|||||||||||||||||||||||